Training MXNet — part 3: CIFAR-10 redux
In part 2, we learned about the CIFAR-10 data set and we saw how to easily load it using a RecordIO object. Using this data set, we both trained a network from scratch and fine-tuned a network trained on ImageNet. In both cases, we used a fixed learning rate and we got to a point where validation accuracy plateaued at about 85%.
In this article, we’re going to focus on improving validation accuracy.
Using a variable learning rate
Let’s fine-tune our pre-trained network again. This time, we’re going to reduce the learning rate gradually, which should help the model converge to a “lower” minimum: we’ll start at 0.05 and multiply by 0.9 each time 25 epochs have gone by, until we reach 300 epochs.
Gradually reducing the learning rate is a key technique in improving validation accuracy.
We need 2 extra parameters to do this:
- lr-step-epochs: the epoch steps when the learning rate will be updated.
- lr-factor: the factor by which the learning rate will be updated.
The new fine-tuning command becomes:
$ python fine-tune.py
--pretrained-model resnext-101 --load-epoch 0000
--gpus 0,1,2,3 — batch-size 128
--data-train cifar10_train.rec --data-val cifar10_val.rec
--num-examples 50000 --num-classes 10 --image-shape 3,28,28
--num-epoch 300 --lr 0.05 --lr-factor 0.9
--lr-step-epochs 25,50,75,100,125,150,175,200,225,250,275,300
A while later, here’s the result.
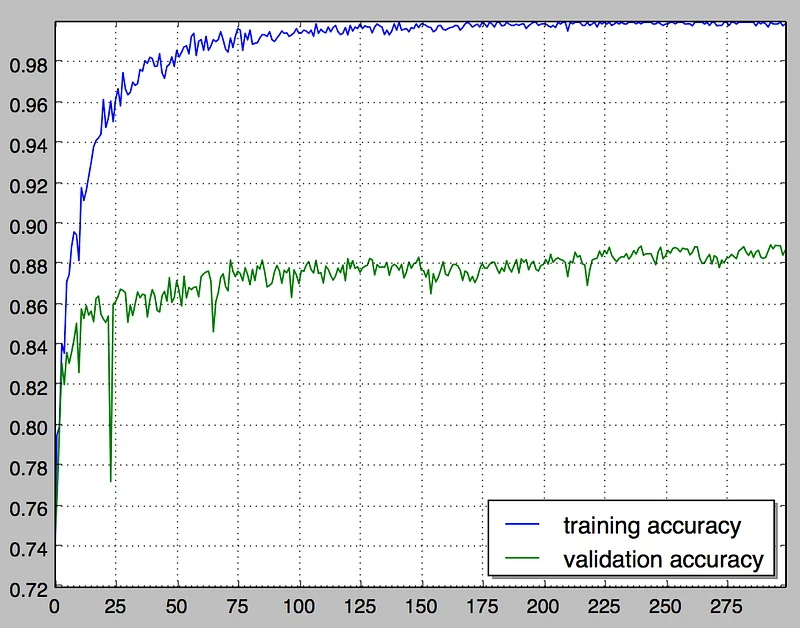
As we can see, reducing the learning rate definitely helps reaching higher validation accuracy. Previously, it plateaued at 85% after 25 epochs or so. Here, it’s climbing steadily up to 89% and would probably keep increasing beyond 300 epochs. 4% is a huge difference: on a 10,000 image validation set, it means that an extra 400 images are correctly labelled.
AdaDelta
Surely, we could keep tweaking and find an even better combination for the initial learning rate, the factor and the steps. But we could also do without all these parameters, thanks to the AdaDelta optimizer.
AdaDelta is a evolution of the SGD algorithm we’ve been using so far for optimization (research paper). It doesn’t need to be given a learning rate. In fact, it will automatically select and adapt a learning rate for each dimension.
Training ResNext-101 from scratch with AdaDelta
Let’s try to train ResNext-101 from scratch, using AdaDelta. Instead of loading the network, we’re going to build one using resnext.get_symbol(), a Python function available in MXnet. There’s a whole set of functions to build different networks: I suggest that you take some time to look at them, as they will help you understand how these networks are structured.
You should now be familiar with the rest of the code :)
These are the results after 300 epochs.
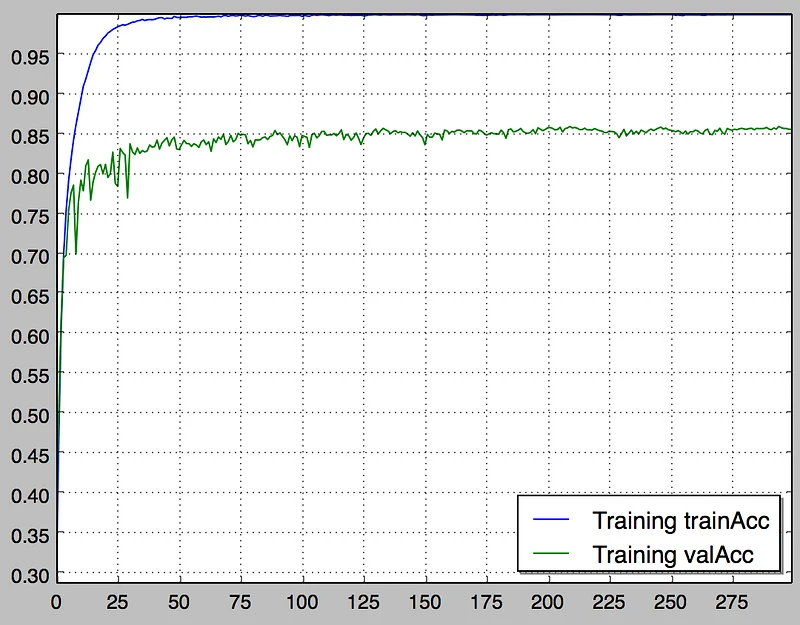
In our previous article, training the same model from scratch only yielded 80% validation accuracy. Here, not only does training accuracy increase extremely fast, we also reach 86% validation accuracy without having to guess about learning rate or when to decrease it.
It’s very likely that an expert would achieve better results by tweaking optimization parameters, but for the rest of us, AdaDelta is an interesting option.
MXNet supports a whole set of optimization algorithms. If you’d like to learn more on how they work and how they differ, here’s an excellent article by Sebastian Ruder.
Fast and Furious
One last thing. I mentioned earlier that training took ‘a while’. More precisely, it took 12+ hours using all 4 GPUs of a g2.8xlarge instance.
Could we go faster? Sure, I could use a p2.16xlarge instance. That’s as large as GPU servers get.
Even faster? We need distributed training, which we’ll cover in part 4.
Thanks for reading :)