Speeding up Apache MXNet with the NNPACK library (Raspberry Pi edition)
In a previous post, I showed you how to add the NNPACK library to Apache MXNet and how this did speed up CPU-based inference for networks such as Alexnet or VGG by a factor of 2 to 3. Definitely worth the effort.
I also mentioned that NNPACK supports ARM 7 processors with the NEON instruction set (similar to AVX for Intel chips), as well as ARM v8 processors (which include NEON by default).
As the Raspberry Pi 3 is built on the Cortex-A53 CPU (ARM v8-based), I figured I’d give it a go and see how NNPACK could help us for embedded applications.

Setup
The steps required to build NNPACK and MXNet are strictly identical to the ones we used on our AWS instance, so please refer to the previous article.
Benchmarks
Given the limited RAM available on the Raspberry Pi 3, we won’t be able to load larger models like VGG16 (as I found out when I first tried loading models on the Pi). Thus, I had to stick to the multi-layer perceptron and the Alexnet convolutional network, with the largest batch sizes possible.
Let’s start with the MLP.
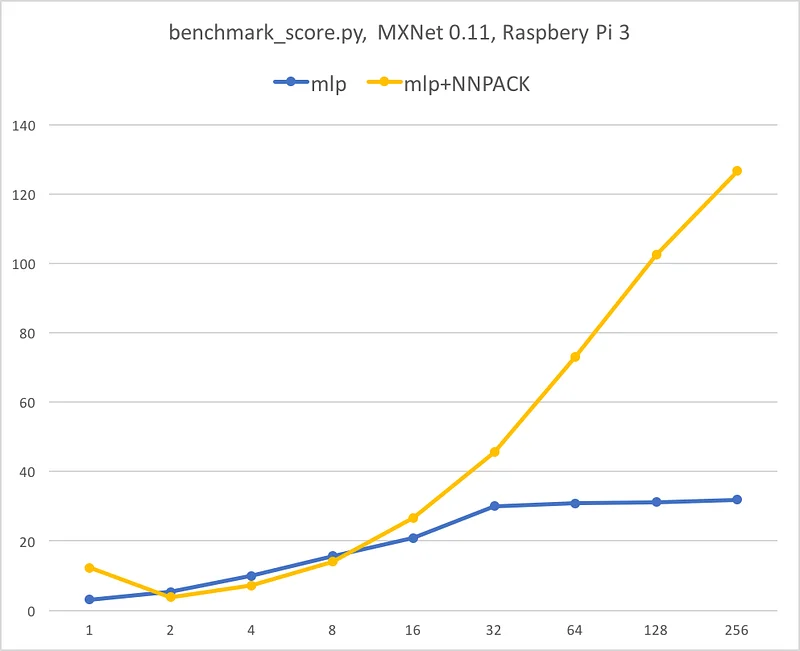
Wow. When processing a single image, we get a consistent 4x speedup. Then, things tend to level (not sure why) before improving again when we really start processing larger batch sizes: 4x speedup is reached again at batch size 256.
Now, let’s try Alexnet now and see what performance boost we get for convolutional networks.
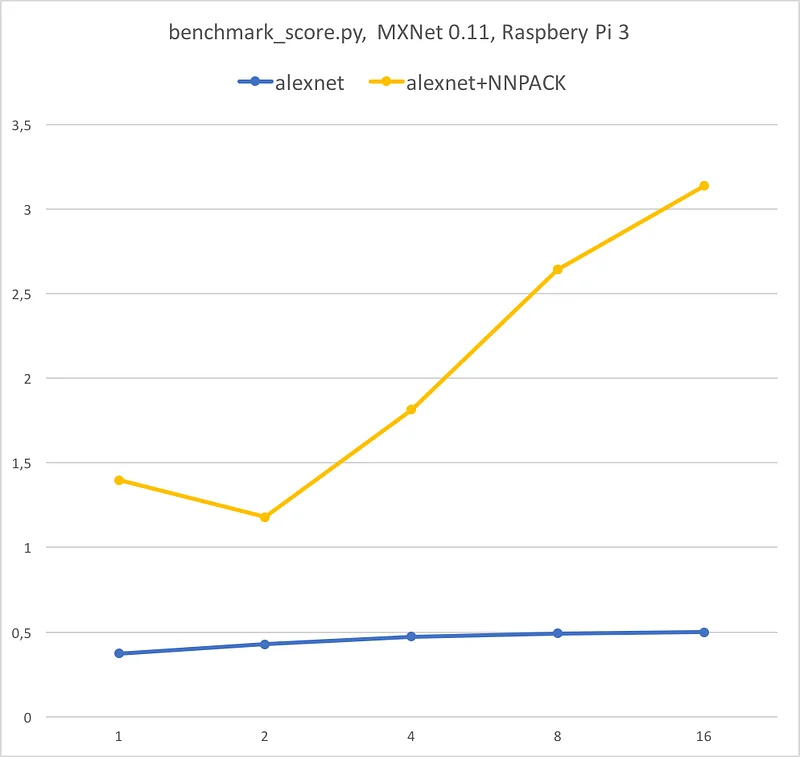
Very impressive. We still get 4x speedup for single-image prediction and exceed 6x speedup for bulk prediction.
Conclusion
We did get a nice speedup on Intel processors, but the optimised code of NNPACK really shines on the less powerful ARM v8. MXNet inference gets a massive performance boost for both single images and larger batches. Kudos to Marat Dukhan, the author of NNPACK.
From this day, NNPACK will be a mandatory build option for MXNet on my Pi. I will definitely keep an eye on future releases :)
That’s it for today, thanks for reading!