ImageNet — part 2: the road goes ever on and on
In a previous post, we looked at what it took to download and prepare the ImageNet dataset. Now it’s time to train!

The MXNet repository has a nice script, let’s use it right away.
python train_imagenet.py --network resnet --num-layers 50 \
--gpus 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 \
--data-train /data/im2rec/imagenet_training.rec \
--data-val /data/im2rec/imagenet_validation.rec
Easy enough. How fast is this running?
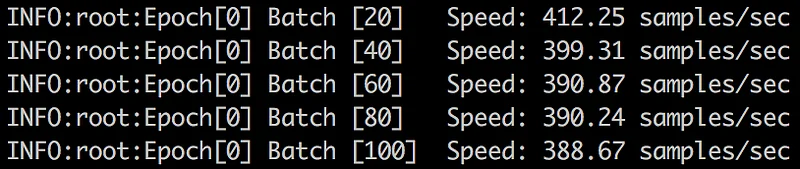
About 400 images per second, which means about 53 minutes per epoch. Over three and a half days for 100 epochs. Come on, we don’t want to wait this long. Think, think… Didn’t we read somewhere that a larger batch size will speed up training and help the model generalize better? Let’s figure this out :)
Picking the largest batch size
In this context, the largest batch size means the largest that will fit on one of our GPUs: each of them has 11439MB of RAM.
Using the nvidia-smi command, we can see that the current training only uses about 1500MB. As we didn’t pass a batch size parameter to our script, it’s using the default value of 128. That’s not efficient at all.
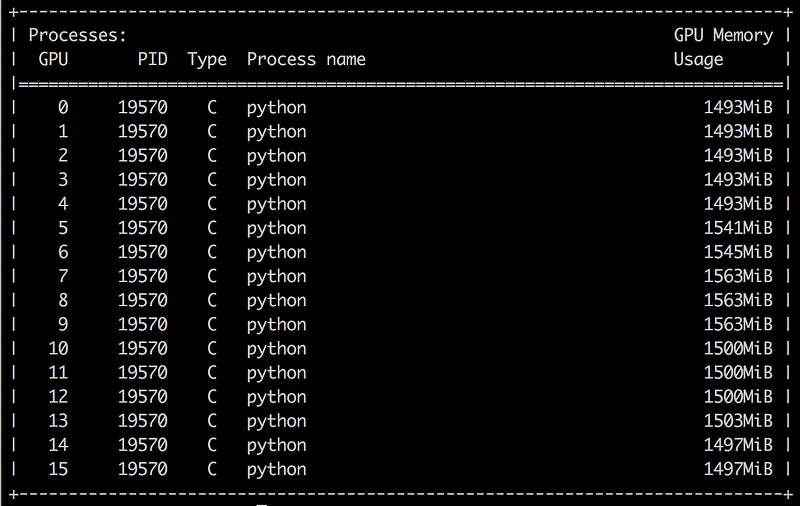
By trial and error, we can quickly figure out that the largest possible batch size is 1408. Let’s give it a try.
python train_imagenet.py --network resnet --num-layers 50 \
--gpus 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 \
--data-train /data/im2rec/imagenet_training.rec \
--data-val /data/im2rec/imagenet_validation.rec \
--batch-size 1408
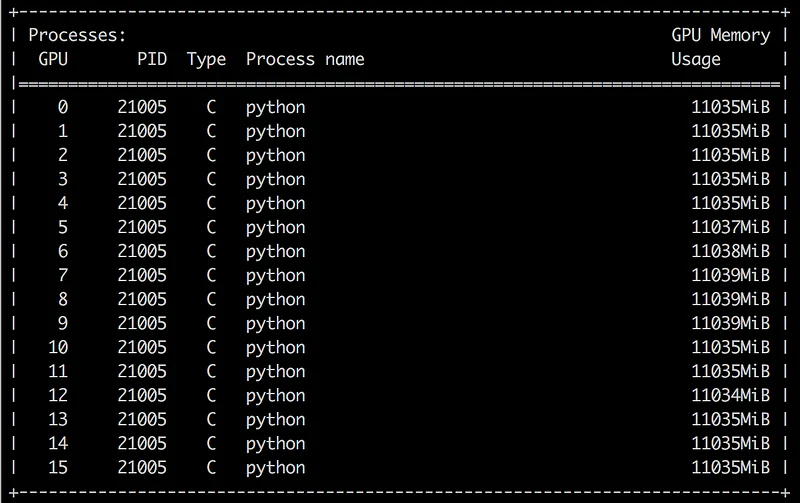
That’s more like it: the GPU RAM is maxed out. Training speed should be much higher… right?
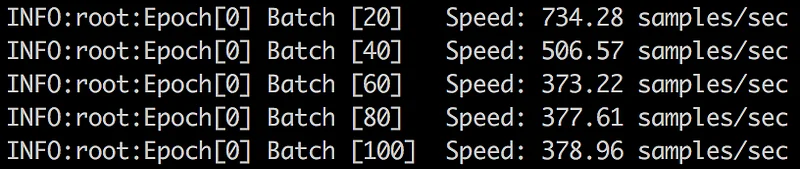
Nope. Something is definitely not right. Let’s pop the hood.
Detecting stalled GPUs
GPU RAM is fully used, but what about the actual GPU cores? As it turns out, there’s an easy way to find out. Let’s look at the “volatile GPU information” returned by nvidia-smi, it’ll give us an idea on how hard GPUs actually work.
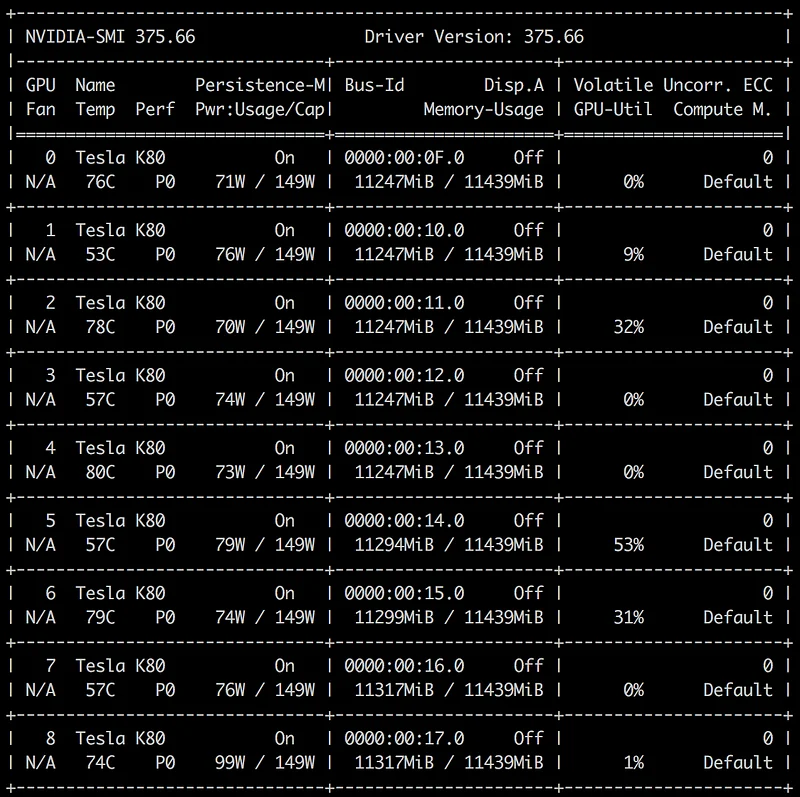
That’s not good. One second, our GPUs are running at 100% and the next they’re idle.
It looks like they’re stalling over and over, which probably means that we can’t maintain a fast enough stream of data to keep them busy all the time. Let’s take a look at our Python process…
Scaling the Python process
The RecordIO files storing the training set are hosted on an EBS volume (built from a snapshot, as explained before). Our Python script reads the images using a default value of 4 threads. Then, it performs data augmentation on them(resizing, changing aspect ratio, etc.) before feeding them to the GPUs. The bottleneck is probably in there.
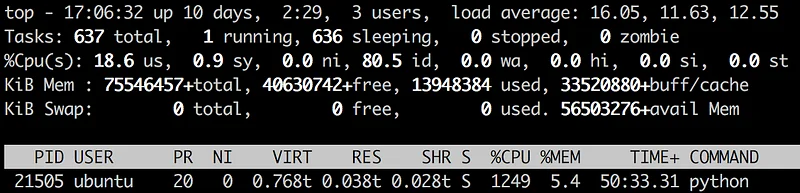
Idle time is extremely high (id=80.5%), but there are no I/O waits (wa=0%). It looks like this system is simply not working hard enough. The p2.16xlarge has 64 vCPUs, so let’s add more decoding threads.
python train_imagenet.py --network resnet --num-layers 50 \
--gpus 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 \
--data-train /data/im2rec/imagenet_training.rec \
--data-val /data/im2rec/imagenet_validation.rec \
--batch-size 1408 --data-nthreads=32
Firing on all sixteen
Our GPUs look pretty busy now.
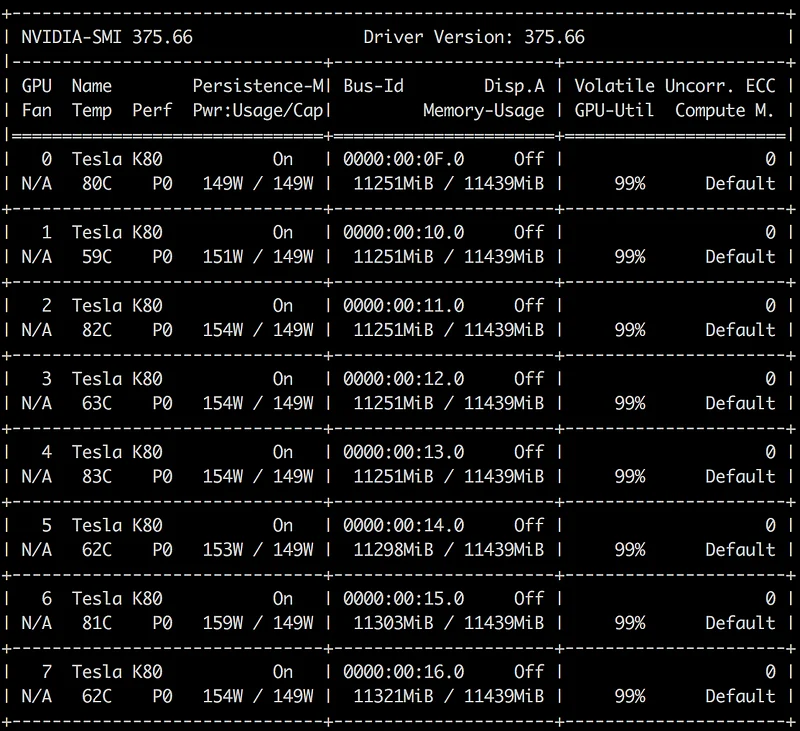
What about our python process?
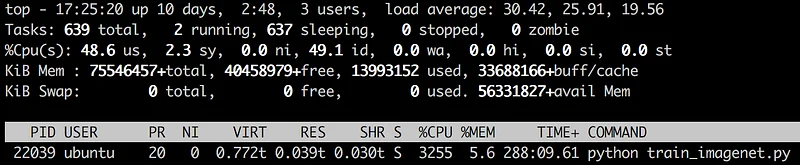
It’s working harder as well, with all 32 threads running in parallel. Still no I/O wait in sight, though (thank you EBS). In fact, we seem to have a nice safety margin when it comes to I/O: we could certainly add more threads to support a larger batch size or faster GPUs if we had them.
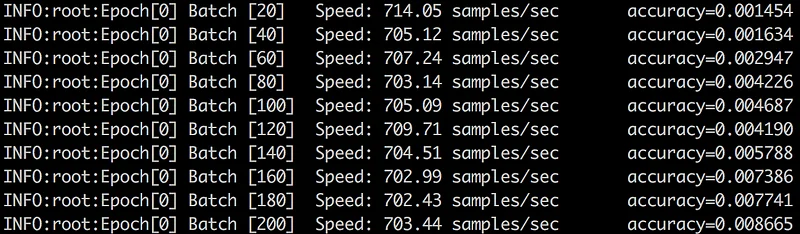
What about training speed? It’s nicely crusing at a stable 700+ images per second. That’s a 75% increase from where we started, so it sure was worth tweaking.
An epoch will complete in 30 minutes, which gives us just a little over 2 days for 100 epochs. Not too bad.
Optimizing cost
At on-demand price in us-east-1, 50 hours of training would cost us $720. Ouch. Surely we can optimize this as well?
Let’s look at spot prices for the p2.16xlarge. They vary a lot from region to region, but here’s what I found in us-west-2 (hint: using the describe-spot-price API should help you find good deals really quick).
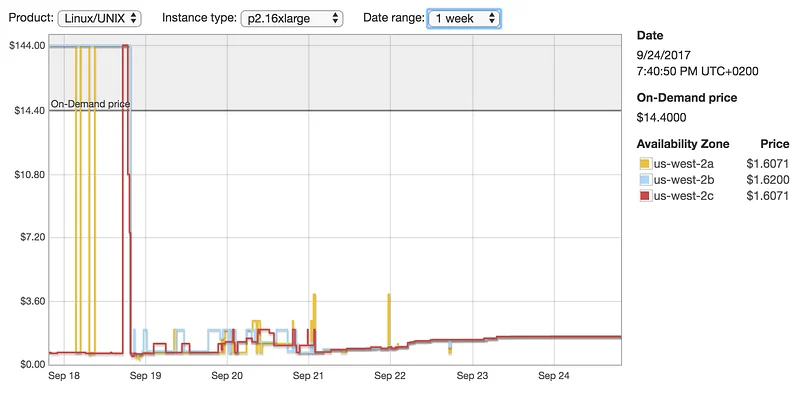
Yes, ladies and gentlemen. That’s an 89% discount right there. Training would now cost something like $80.
Conclusion
As you can see, there is much more to Deep Learning than data sets and models. Making sure that your infrastructure runs at full capacity and at the best possible price also requires some attention. Hopefully, this post will help you do both.
In the next post, I think we’ll look at training ImageNet with Keras, but I’m not quite sure yet :D
As always, thank you for reading.
Congratulations if you caught the Bilbo reference in the title. You’re a proper Tolkien nerd ;)