Speeding up Apache MXNet, part 3: let’s smash it with C5 and Intel MKL
In a previous post, I showed you how to speed up MXNet inference with the NNPACK Open Source library.
Since then, AWS has released a new instance family named c5, based on the new Intel Skylake architecture. This architecture notably uses the AVX-512 SIMD instruction set, which is designed to boost math operations involved in Deep Learning. To maximize performance, developers are encouraged to use the Intel Math Kernel Library which provides a highly optimized implementation of these math operations.
How about we combine C5 and MKL and get smashin’?

Building MXNet with MKL
The procedure is pretty simple. Let’s start with a c5.4xlarge instance 16 vCPUs, 32GB RAM) running the latest Deep Learning AMI.
First, we need to configure the MXNet build in ~/src/mxnet/config.mk. Please make sure that the following variables are set correctly.
Now, let’s build the latest version of MXNet (0.12.1 at the time of writing). The MKL library will be downloaded and installed automatically.
Time for a quick check.
We’re good to go. Let’s run our benchmark.
Running the benchmark
Let’s use the script included in the MXNet sources: ~/src/mxnet/example/image-classification/benchmark_score.py. This benchmark runs inference on a synthetic data set, using a variety of Convolutional Neural Networks and a variety of batch sizes.
As nothing is ever simple, we need to fix a line of code in the script. C5 instances don’t have any GPU installed (which is the whole point here) and the script is unable to properly detect that fact. Here’s the modification you need to apply. While we’re at it, let’s add additional batch sizes.
OK, now let’s run the benchmark. After a little while, here are the results.
For comparison, here are the same results for vanilla MXNet 0.12.1 running on the same c5 instance.
So how fast is this thing?
A picture is worth a thousand words. The following graphs illustrate the speedup provided by MKL for each network: batch size on the X axis, images per second on the Y axis.
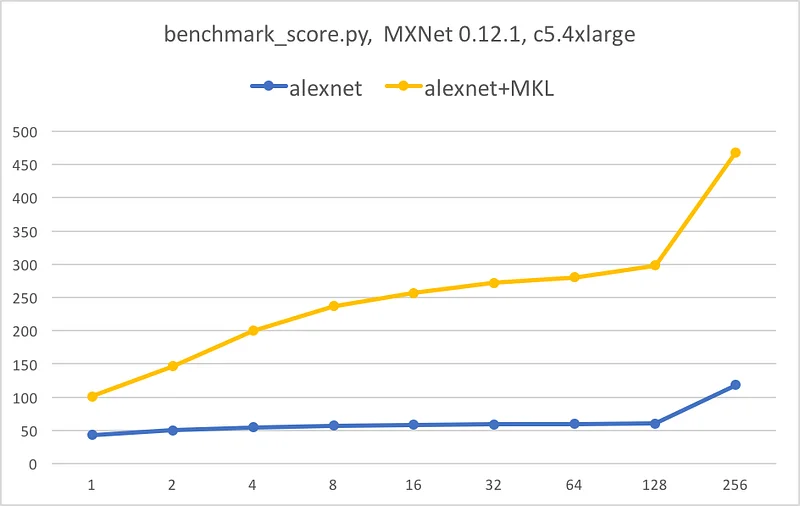
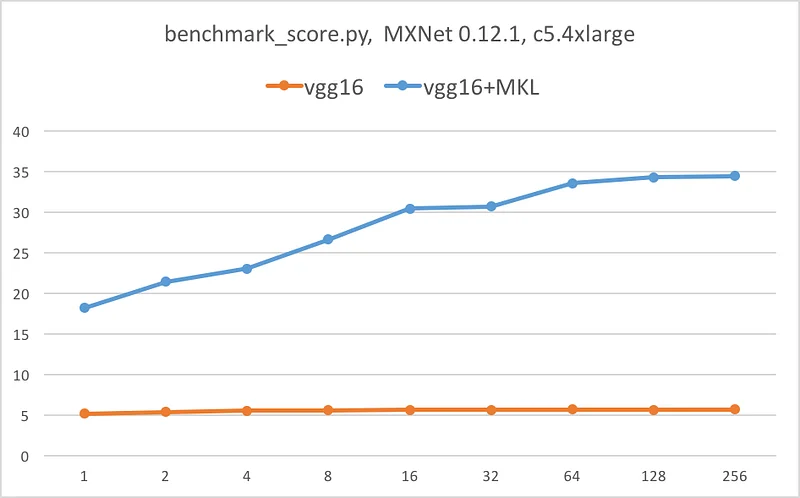
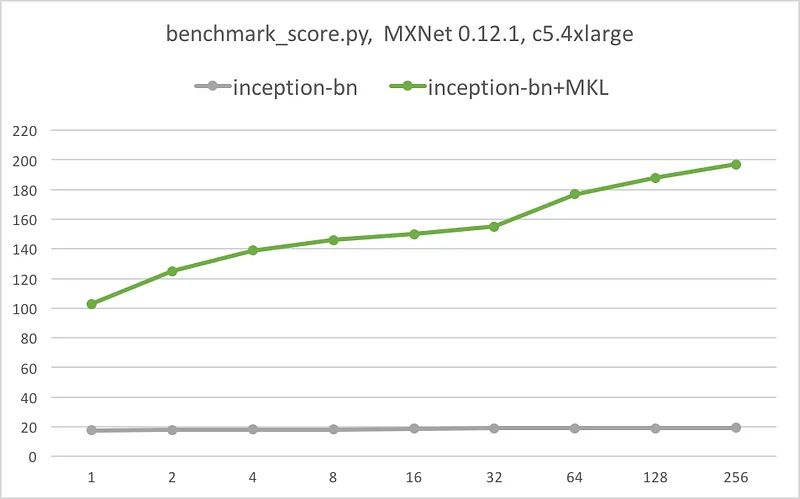
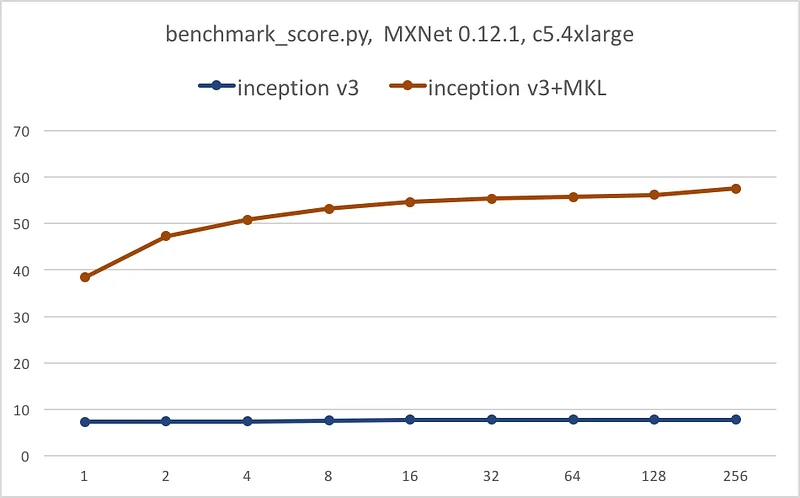
Conclusion
Do we need one? :) Thanks to Intel MKL, we get massive inference speedup for all models, anywhere from 7x to 10x. We also get some scalability as AVX-512 kicks into high gear when batch size increases.
The comparison with vanilla MXNet 0.11 running on a c4.8xlarge instance is even more impressive, as speedup consistently hits 10x to 15x. If you’re running inference on c4, please move to c5 as soon as you can: you’ll definitely get more bang for your buck.
One last thing: what about training? Using the same c5 instance, a quick training test on CIFAR-10 (using the train_cifar10.py script) shows a 10x speedup between MKL-enabled MXNet and vanilla MXNet. Not bad at all. On smaller data sets, c5 could actually be a cost-effective solution compared to GPU instances. Your call, really… which is the way we like it ;)
That’s it for today. Thanks for reading.
We smashed it, so yeah, this kind of applies.