A quick look at Automatic Speech Recognition with Amazon Transcribe
Amazon Transcribe is a new service announced at AWS re:Invent 2017.
At the moment, the service is only available in preview (which you can apply for), but this shouldn’t prevent us from taking a look, should it? ;)
Features
This is what Amazon Transcribe is capable of right now:
- Offline processing of audio files stored in S3.
- Languages: English, Spanish.
- File formats: WAV, mp3, mp4, FLAC.
- Sampling rate: from 8KHz (telephony audio) to 48Khz.
- Duration: maximum 2 hours.
API
This is a high-level service in the vein of Polly and Rekognition, so the API is as easy as it gets: ListTranscriptionJobs, StartTranscriptionJob and GetTranscriptionJob.
No CLI for now, so we have to test either with the AWS Console or with the SDK. Let’s keep this simple and try the console.
Creating a job
I recorded a sound file, saved it as a FLAC file and uploaded to S3. I also updated the bucket policy to allow access for Transcribe (you’ll find the policy in the documentation).
Heading out to the console, it’s pretty easy to create a job. Just make sure you use a proper URL to point to your sound file, not an S3 URI.
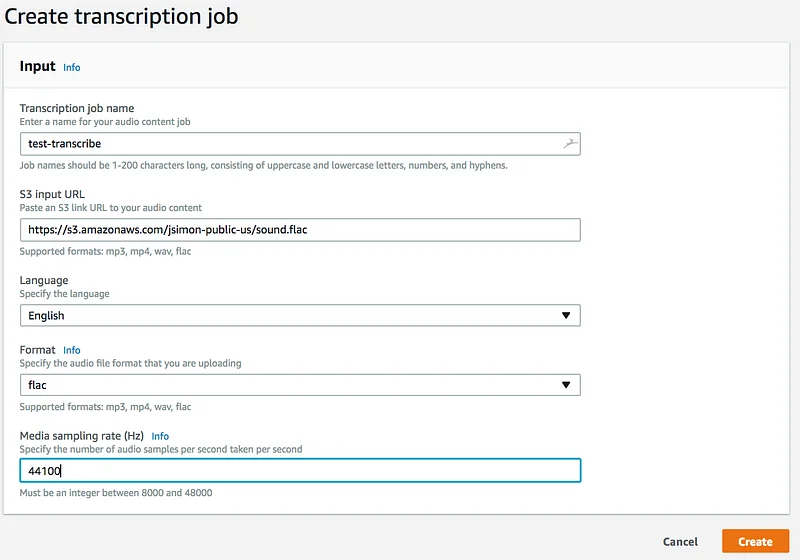
Click on the “Create” button, wait for a few minutes and you’ll see the output of the job.
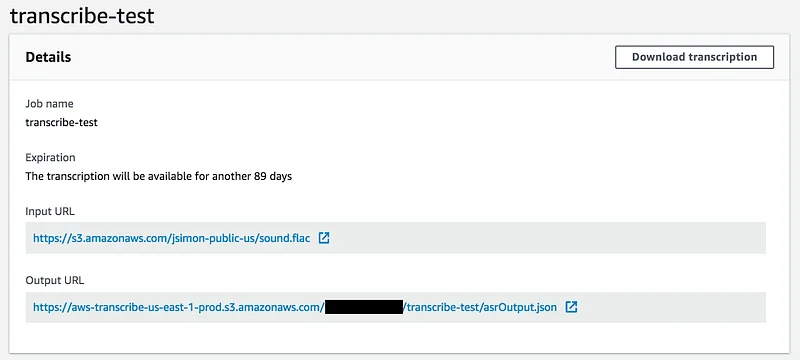
Let’s download the JSON file (complete file) and look at the raw output.
Hello my name is julian and i live in paris france right now i'm recording a sound file because i would like to test a new service called amazon transcribed this file should be long enough to give me a good sample and hopefully transcribed will be able to understand my french accent. And if not well that should make for a pretty funny transcription. This should be long enough by now so let's stop the recording upload that file and get some results.
Pretty good results. Some commas are missing and funny enough, Transcribe doesn’t understand its own name. Apart from this, this is an accurate transcription of my sound file.
The output file also contains the time stamps for each words, the confidence score and possible alternatives, e.g.:
"items": [
{
"start_time": "0.600",
"end_time": "1.030",
"alternatives": [
{
"confidence": "1.0000",
"content": "Hello"
}
],
"type": "pronunciation"
},
{
"start_time": "1.310",
"end_time": "1.520",
"alternatives": [
{
"confidence": "1.0000",
"content": "my"
}
],
"type": "pronunciation"
},
{
"start_time": "1.520",
"end_time": "1.680",
"alternatives": [
{
"confidence": "1.0000",
"content": "name"
}
],
"type": "pronunciation"
},
{
"start_time": "1.680",
"end_time": "1.810",
"alternatives": [
{
"confidence": "1.0000",
"content": "is"
}
],
"type": "pronunciation"
},
{
"start_time": "1.810",
"end_time": "2.280",
"alternatives": [
{
"confidence": "0.9775",
"content": "julian"
}
],
"type": "pronunciation"
},
Cool new service. Please join the preview and send us feedback. I’m very curious to see what you’re going to build with this!
As always, thank you for reading.