A quick look at the Swish activation function in Apache MXNet 1.2
Apache MXNet 1.2 is right around the corner. As hinted at by the change log, this looks like a major release, but in this post, we’ll focus on a new activation function: Swish.
A quick recap on activation functions
In deep neural networks, the purpose of the activation function is to introduce non-linearity, i.e. to enforce a non-linear decision threshold on neuron outputs. In a way, we’re trying to mimic — in a simplistic way, no doubt — the behavior of biological neurons which either fire or not.
Over time, a number of activation functions have been designed, each new one trying to overcome the shortcomings of its predecessors. For example, the popular Rectified Linear Unit function (aka ReLU) improved on the Sigmoid function by solving the vanishing gradient problem.
Of course, the race for better activation function never stopped. In late 2017, a new function was discovered: Swish.
The Swish function
By automatically combining different mathematical operators, Prajit Ramachandran, Barret Zoph and Quoc V evaluated the performance of a large number of candidate activation functions (“Searching for Activation Functions”, research paper). One of them, which they named Swish, turned out to be better than others.
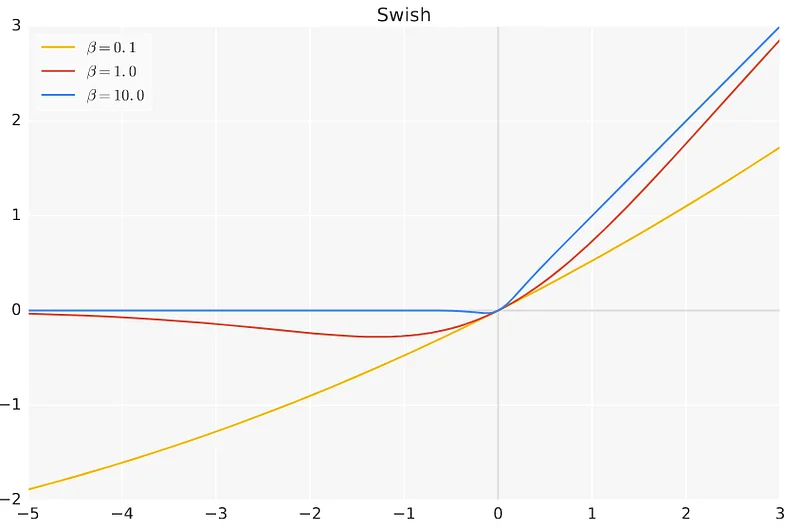
As you can see, if the β parameter is small, Swish is close to the linear when the β parameter is small and close to ReLU when it’s large. The sweet spot for β seems to be between 1 and 2: it creates a non-monotonic “bump” for negative values which seems to have interesting properties (more details in the research paper).
As highlighted by the authors: “simply replacing ReLUs with Swish units improves top-1 classification accuracy on ImageNet by 0.9% for Mobile NASNet-A and 0.6% for Inception-ResNet-v2”.
This sounds like an easy improvement, doesn’t it? Let’s test it on MXNet!
Swish in MXNet
Swish is available for the Gluon API in MXNet 1.2. It’s defined in incubator-mxnet/python/mxnet/gluon/nn/activations.py and using it in our Gluon code is as easy as: nn.Swish().
In order to evaluate its performance, we’re going to train two different versions of the VGG16 convolution neural network on CIFAR-10:
- VGG16 with batch normalization as implemented in the Gluon model zoo, i.e. using ReLU (incubator-mxnet/python/mxnet/gluon/model_zoo/vision/vgg.py)
- The same network modified to use Swish for the convolution layers and the fully connected layers.
This is pretty straightforward: starting from the master branch, we simply create a vggswish.py file and replace ReLU by Swish, e.g.:
self.features.add(nn.Dense(4096, activation='relu', weight_initializer='normal', bias_initializer='zeros'))
--->
self.features.add(nn.Dense(4096, weight_initializer='normal', bias_initializer='zeros'))
self.features.add(nn.Swish())
Then, we plug this new set of models into incubator-mxnet/python/mxnet/gluon/model_zoo/__init__.py and voila!
Here’s the full diff if you’re interested. There’s really not much to it.
Of course, you’ll need to build and install: you should know how to do this by now ;) If you’ve already built the master branch, you can get away with just installing the Python API again. If you’re not comfortable with this, no worries: just wait for an official 1.2 installation package :)
Training on CIFAR-10
MXNet contains an image classification script which lets us train with a variety of network architectures and data sets (incubator-mxnet/example/gluon/image_classification.py). Exactly what we need!
We’ll use SGD with epochs steps, dividing the learning rate by 10 each time.
python image_classification.py --model vgg16_bn --batch-size=128 --lr=0.1 --lr-steps='10,20,30' --epochs=40
python image_classification.py --model vgg16_bn_swish --batch-size=128 --lr=0.1 --lr-steps='10,20,30' --epochs=40
Here are the results.
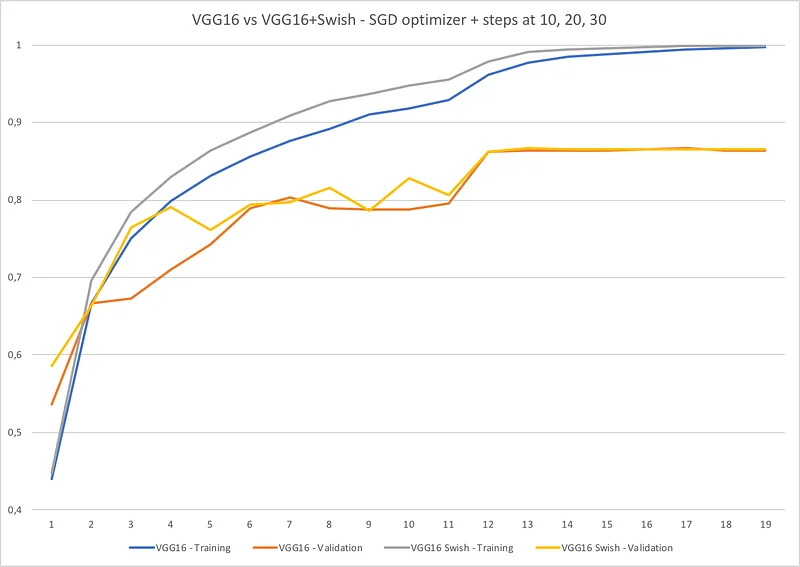
It’s always difficult to draw conclusions from a single example (although I did run a bunch of different trainings with consistent results). Here, we can see than the Swish version seems to train faster and validate as well as the ReLU version.
Top validation accuracies are respectively 0.866186 at epoch #14 and 0.866001 at epoch #19. A minimal difference, but then again VGG16 isn’t a very deep network.
Conclusion
So now we have another activation function in our arsenal. It’s still quite new, so we need to experiment and learn when to use it or not. In case you’re curious, MXNet 1.2 also adds support for the ELU and SELU functions, so why not read about these as well? A Deep Learning engineer’s day is never done :)
That’s it for today. Thank you for reading. Happy to read your feedback here or on Twitter.
This post was written in New Orleans, so obviously…